Word-to-Vector Embeddings II
Backpropagation
From the previous essay, we went through some layers, handling our data and using various weights and techniques to reach our initial guess at the true sentiment of a sentence (whether it is positive, negative or neutral). Next step, for any deep neural network, si simply to backpropagate, or see what changes we must make in our parameters in order to improve our guess. As always, we will use a Loss function, and an optimization algorithm in order to calculate the required gradients (if any of these terms are unclear, please go through my previous essays, or google for a brief understanding). We begin with defining our parameters and inputs, and working our way to a loss function. The transformation matrices below are simply a means to attaining the averaging and reduction.
With the above given inputs and paramters, we can go through the forward propagation process again like so:
And with this, our model has given us it's very first guess of what the statement's sentiment can be. It's wrong, and we know it. We just need to let the model know how wrong it is, and in which direction it should go next in order to achieve better results. Our, or rather the model's next step will be calculating the gradients of the weights with respect to the lost function. We must therefore first define a loss function, and see how the actual gradient calculation would look like. For the loss function, we will use our dear old mean squared error, were we simply subtract our guess from the real value, where the real value is the true sentiment of the sentence. Let the true value be represented by **T**. With that, our loss function becomes,
To begin with, we must recognize what our parameters are in the above equation, and what're the constants that are of no use to us. The paramter (in this case), is simply the weight matrix **W**1, where as the other transformation matrices aren't really paramters but just helper matrices. **S** is our input, since it is constructed by taking in our sentence vector, and **T** is the ground truth, and hence the input and output are merely constants in the above equation (since we cannot change them in any way). With this, our next step becomes very simple: just calculate the gradient of the weight matrix with respect to the loss function:
This gradient is simple enough to calculate by hand, but thats not how our model will do it, so lets use our computer's method: making a computational graph, and using it to *back*-propagate in order to find our gradient. With defining the intermediate variables, we can make a computational graph for this particular model like this:
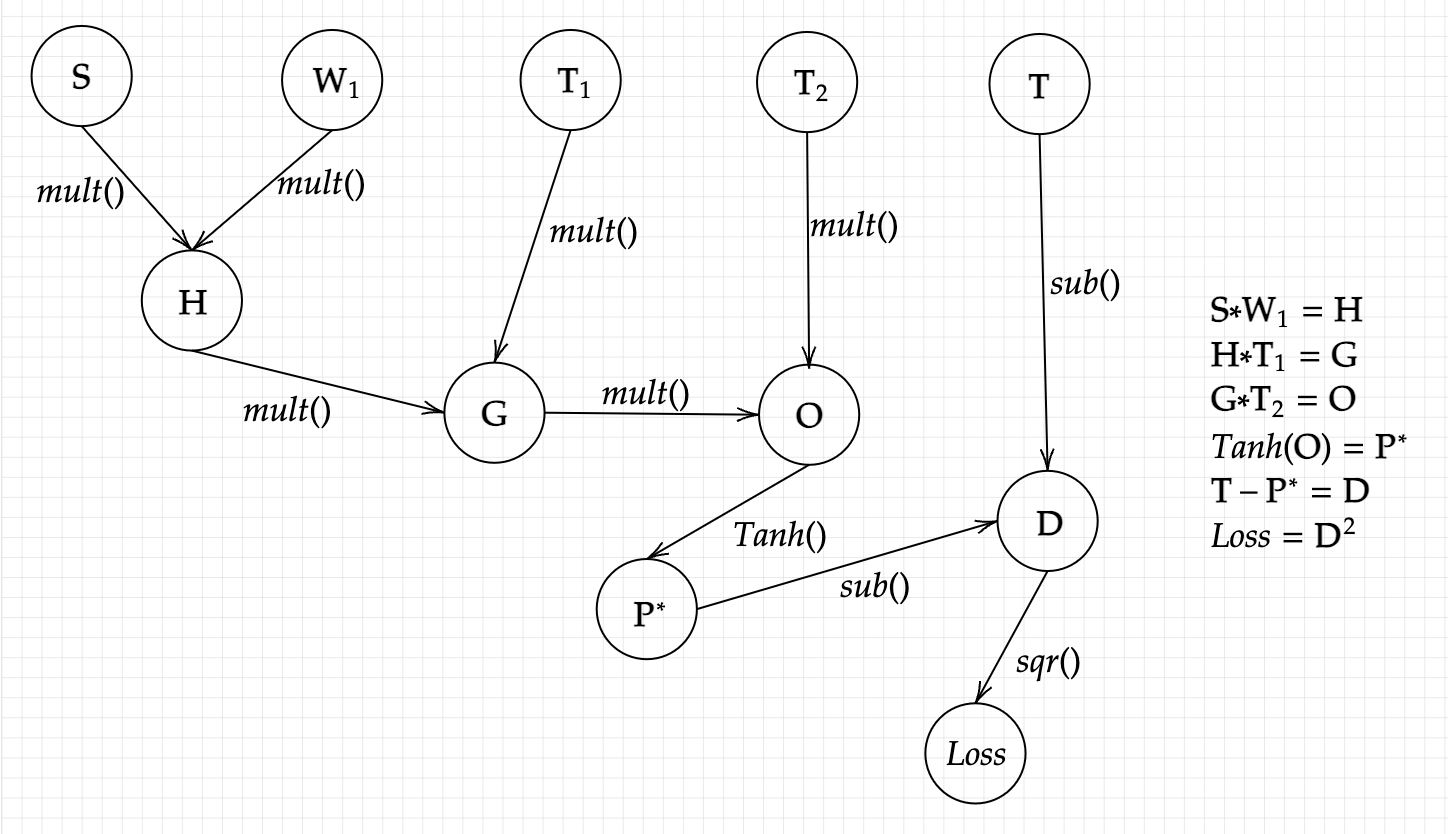 And our desired gradient being :
And our desired gradient being :
For the sake of simplicity, I have calculated the gradients for each inidivisual term, Note: If this seems unfamiliar, readthis essay
And put them together in our final gradient, the term that will be subtracted from the weight matrix:
Expanded:
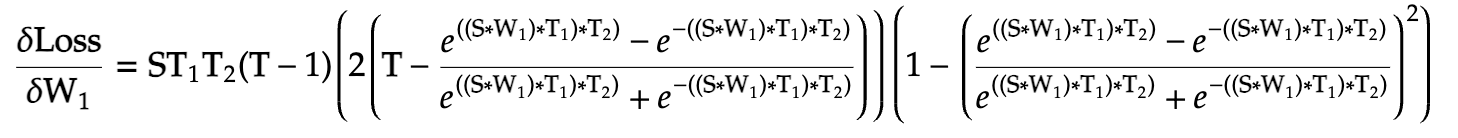 With this, we have finally arrived at the last and final step of this iteration: to simply subtract this gradient form the weight matrix and *learn* from our mistakes (or rather the model's mistakes),
With this, we have finally arrived at the last and final step of this iteration: to simply subtract this gradient form the weight matrix and *learn* from our mistakes (or rather the model's mistakes),
Our model has finally learned from it’s mistake, ounce. We simply have to keep doing the results until we can get to sufficiently low loss function (but not zero, or too low).
Internal Meaning
After coming this far, you must be wondering, what on earth has this got to do with understanding language at all ? All we did was a bunch of linear algebra! Where was the part where our model/network understands language? You feel that way partly because we tackled this problem with pure mathematics, and hence it is very tough to see any intuitive meaning beyond what we see mathematically. If we had actually coded this model, it would still be a bit unclear. Thus for further clarity and to actually show what exactly did our model learn, and why this technique, though seemingly random at first, has very fascinating results, we can easily get an example. For this purpose, I had trained a model on the previous techniques (though I used some more layers), on a bunch of positive, negative and neutral sentences and had it guess the sentence’s sentiment. Our model, in order to guess the sentiment of a sentence, must find correlations between the words that make up the sentence, and use those correlations to predict the sentiment. For instance, it might associate the word ‘beautiful’ with a positive sentiment, and the word ‘terrible’ with a more negative sentiment, as in if these words appear in a sentence, the guess would slightly (or significantly, depends on the sentence), tilt towards the associated sentiment, i.e, a sentence with ‘beautiful’ in it might more probably be a positive one, and a sentence with ‘terrible’ in it will more probably be a negative one. So, we simply write a function that finds words that the model thinks are similiar to the word ‘beautiful’. Here are the results:
And here are the results for using the same function on the word ‘terrible’:
The first time I saw this results, I was amazed! It was just mind-blowing how, after doing seemingly very simple math(!), like linear algebra, a computer program was able to find (or guess?) the intrinsic meaning of words! From the above results, we can clearly see that our model has correctly (somewhat) found correlations between certain words, and how these words have certain underlying meanings that could be captured in a weight matrix. The model was able to determine that the words ‘beautiful’, ‘wonderful’ and ‘lovely’ have a certain correlation with being positive, and certain other words like ‘terrible’, ‘depressed’ or ‘ruined’ are more similiar, as they are correlated with being negative. If you notice, it also associated the word ‘leadership’ with ‘terrible’, that could be mistake, OR that word was more likely used in a negative statemant. Mind you, this is a very rudimentary model, trained for only 10 iterations, and still produced such wonderful results! As we add more layers (make it more complicated), or use different architectures, we can be ever so close to understanding some portion of our natural language.