Exploring Architectures- CNN II
Building upto: Backpropagation
With our loss function defined in the previous essay, we arrive at perhaps the most important and complex part of the network (any network that is), backpropagation. We start by doing a small recap of all the operations we have done to get to our probability distribution, and put that in our loss function. As a starting point, let’s define an operation to denote a convolution, and ounce again follow the entire process (bit lenghty, but helps for revision).
In the last layer, the various parameters that 𝜃 represents are simply the weights, biases and the kernel. Parameters are objects (matrices and vectors in our case) that our model used in order to arrive at the probability distribution and the ones it is allowed to tweak and adjust. The only other variables are the input and the output, which we provide and which can’t be tampered with, hence they are always constant. For the ease of backpropagation, let’s pull the variables in the loss function.
This is the cross entropy loss. With the input layer I which is the image, we utilize the parameters W1,W2,B1,B2 and K to calculate a certain probability distribution or at least our model’s initial guess at the true distribution T. After that we simply check how wrong it was by using the cross entropy loss. Here : P * ( y | x ; 𝜃) is the probability that our model came up with using the parameters, and P(y|x) is the true probability or T.
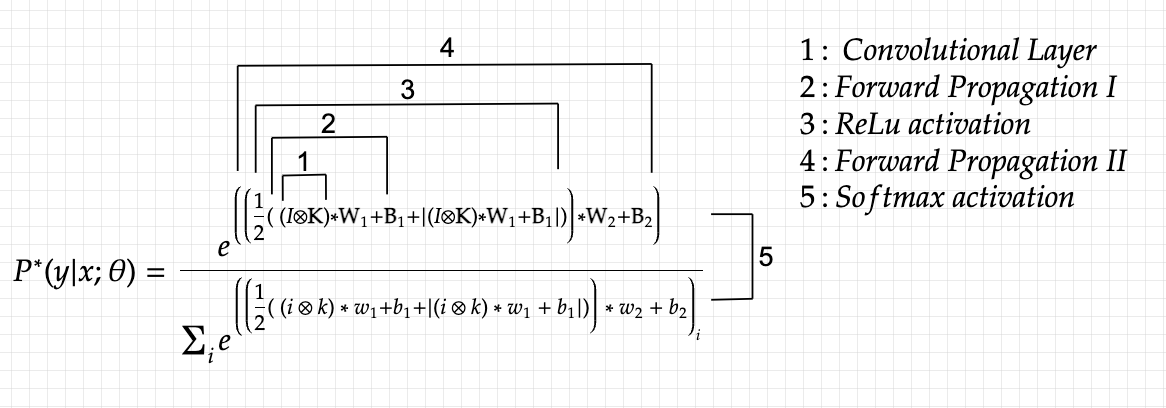
The above loss function is made up of: input I and output T, which cannot be tampered with and are constants, and parameters which the model must modify and tweak, in order to bring down the overall loss function (W1,W2,B1,B2 and K). The reason the above equation looks so complicated is due to the fact that I put each and every variable in terms of either the input or one of the parameters. It need not be so complicated, but since mathematical theory requires it (and it’s fun as well), I tried my best. Perhaps the most difficult part is yet to come: we must find the derivative of the loss function with respect to each of the parameters, in order to perform gradient descent optimization.
Backpropagation
As discussed in previous essays, the above derived loss function must be minimized. But how ? In order to answer that question, we must remember how it was formed in the first place: through the use of certain parameters (mathematical objects of our/model’s desire) and real world data that we obtained (I and T for input and the actual true values of the output). We adjust the parameters after every iteration in such a way that it minimizes the loss function. By how much should be change the parameters? By the loss’s derivative with respect to the parameters. This is one of the most important optimization algorithms in deep learning, known as gradient descent optimization. (For further details, read my previous essayhere).
For us to solve the various gradients with respect to our inputs by hand is already a very tedious task: as we have an already very complex loss function with multiple inputs. But nevertheless, I have broken down the equation into various parts and constructed a computational graph for the same, where we can more easily see what’s happening under the hood and also easily calculate derivatives of more simpler functions and than to pile them up. First we start by assigning sub-variables and creating what we call a computational graph (I would highly recommend readingthis essay before going on, as it will make things crystal clear).
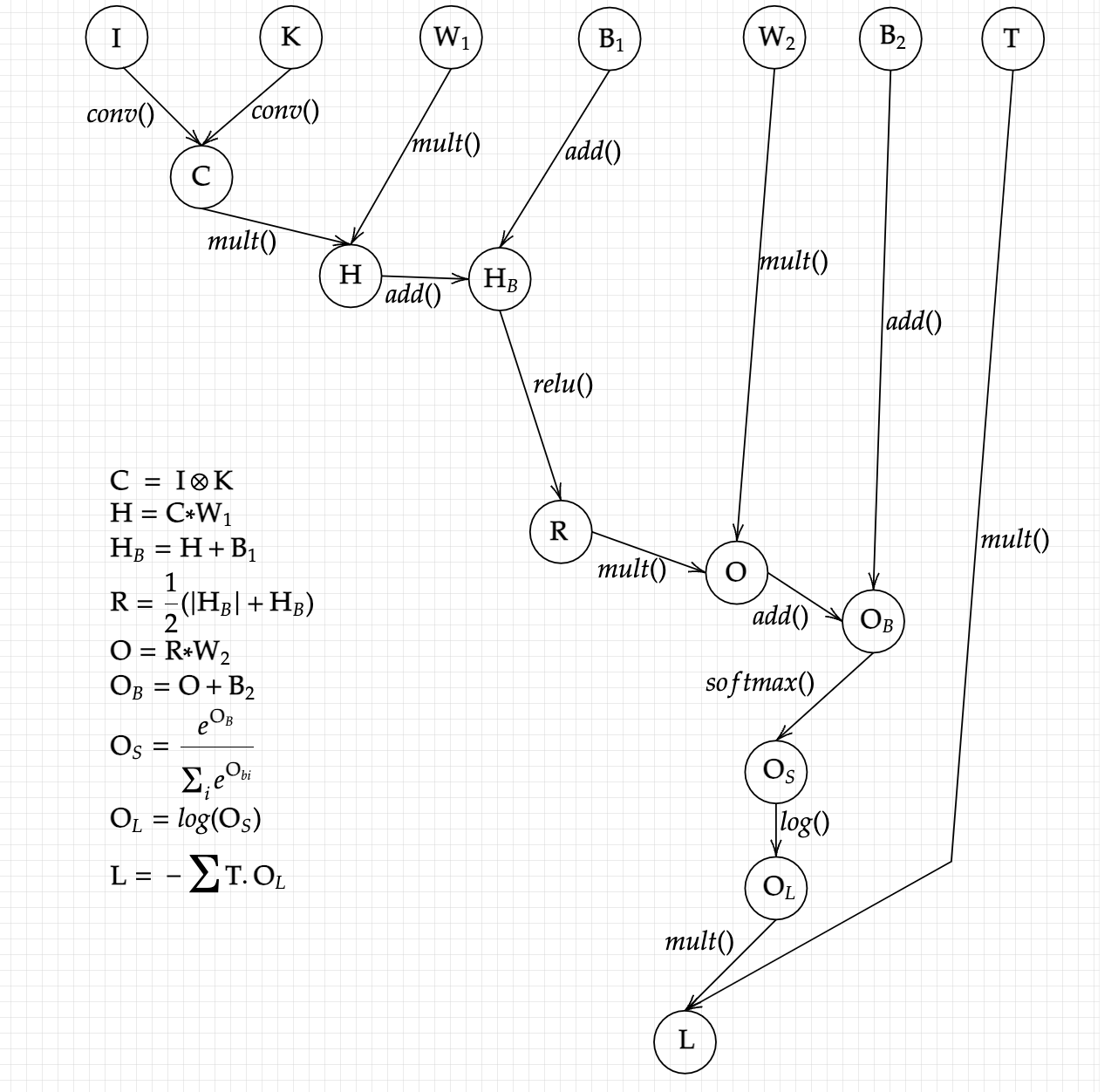
Thus we have formed our graph, with each sub-variable repesenting an operation performed on our original parameters or Input in order to reach our output. This view is much simpler, and makes it easier to get to the next step, where we want to calculate each variable’s gradient with respect to the variable that were used in creating it. Before that, let’s view notationaly what we want: the derivative of the Loss function with respect to W1, B1, W2, B2, K.
In order to get to these, we just need to traverse the graph backwards and get to the final output, hence backpropagation. Since the values are too complex, I have first calculated the indivisual gradients of sub-variables as follows:
And finally, through the chain rule, we get to our final parameter gradients:
By substituting the above equations with their actual values, we see that the gradients are indeed quite complex, despite us dealing with a fairly rudimentry network. All that remains is that we change the parameters by their gradients and keep continuing the process until we reach a desired loss level.
Ok. That was a lot of calculations and maths to deal with ! This entire process discussed above and in the previous essay constitutes the convolutional nueral network, which gives computers vision. More sophiticated models are far more complex and larger in their parameter size and numbers (as many might know, chatGPT has 175 billion paramters, compared to the measly five we used here). But no model strays too far away from the basic architecture, and hence we always benefit from knowing these architectres inside out. Believe it or not, the entire process above can be acheived in just a few lines of code using certain deep learning framworks (PyTorch or Tensorflow). Anyways, thank you for reading this far!