Automatic Differentiation II
In the last essay, we saw how we can calculate the gradients of scalar functions, by implementating backpropagation through a graph data structure. The implementation process was preceded by the theory behind both the graph data structure and the chain rule. The final algorithm was very useful in calculating scalar values, but we must not forget multi-dimensional inputs. At times (most of the times actually), we need gradients on vector valued functions, not scalar. Therefore, in this continuation essay, we shall explore Vector calulus and how it fits in Automatic Differentiation.
Vector Calculus
There isn’t as much difference in this topic, compared to normal calculus. Topics that are generally taught under this concept such as Divergence, Curl, Line Integrals .. etc. won’t be covered here (anyone interested can exploreKhan academy, for their excellent courses), as they are not relevant in ML/DL. We shall only go over the general cases, and put them in our algorithm. A vector is simply a list of numbers put together,
Where R denotes the set of all real numbers. What we are interested in, is what is the derivative of a vector with respect to another vector. As I covered this in another essay as well (Neural Networks through Linear Algebra), it results in what we call a Jacobian. Let v and x be two vectors,
If we need to find out the derivative of v with respect to x, we get a Jacobian Matrix.
Generally when we deal with multi-dimensional data, we need to pay special attention to the dimensions. In the above example, we see how the matrix combines the dimensions of the two vectors, to give us an *n * m* dimensional matrix. The reason is simple: we simply calculated the derivative of each element in v with respect to each element in x, and put them all in the matrix. When it comes to the derivative of a matrix with respect to a vector, the same process applies, and we get a three-dimensional Jacobian cube structure. But a more easier process would be to simply reshape the matrix into a vector. Let M be a matrix, of dimensions *r * y*.
Reshaping the matrix into a vector would give us a vector of ry dimensions. This can be done because there exists an isomorphism (they are similiar, or have similiar/same properties) between R*r * y* and Rry. The matrix M after reshaping looks like this,
After reshaping, calculating the derivative with respect to any other vector is simply to follow the previous steps, to get a Jacobian matrix.
Doing so, we basically get the same Jacobian cube as before, as you can check with the dimensions (*r * y * m* = *ry * m*), because all we did was reshape the matrix for easier calculations and understanding. With this, we can move forward to see how to backpropagate with vector-valued functions.
Backpropagation with Vectors
As we did before, it would benefit us if we applied this theory with a numerical example in mind. Let us define two vectors,
And going further, we can define an equation using them as our primary variable,
Thus we have the value of z vector, with the dimensions being (1 x 5). Going further, before we begin with calculating the gradients, let’s visualize it in a graph data structure, where we need two more sub-variables: u = x2 and v = y2
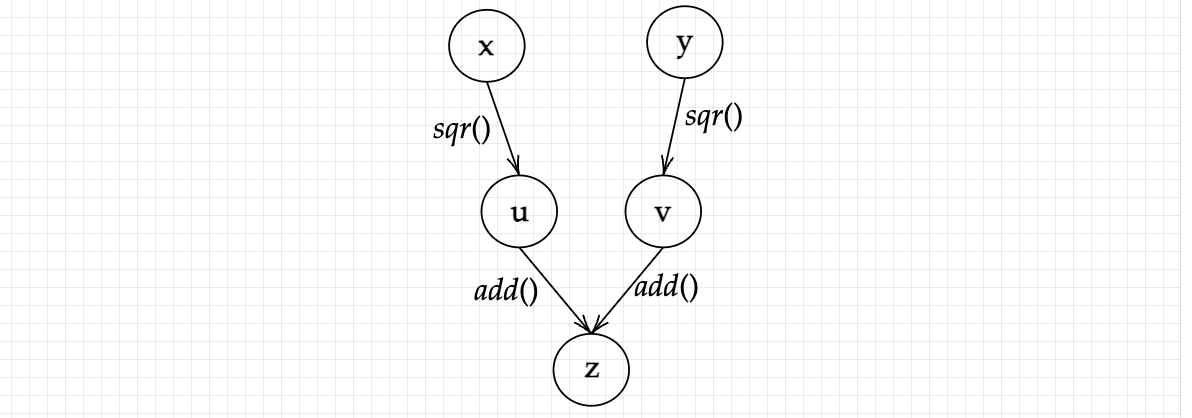
Upto here, we are in similiar territory as scalar valued functions. But as we shall see, while backpropagating from here, we observe a change in dimensions which needs to be dealt with. Going back as usual leads us to the following equations:
As was in the previous essay, the graph looks like this:
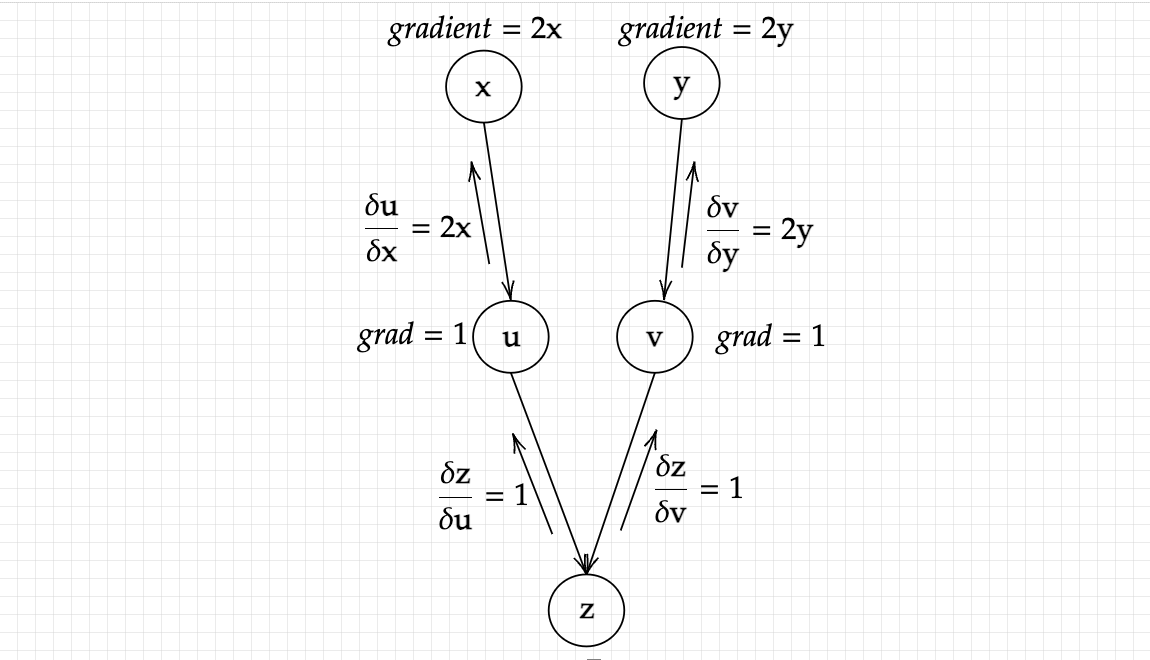
One thing that we must remember is that the expressions of partial derivatives represent matrices and not simple vectors. This can prove somewhat troublesome while implementing practically, as the gradients as passed backwards, they are needed for further computations, which can become complicated quickly as the dimensions increase rapidly, and sort of accumulate. For instance,
Is already a matrix R*5 * 5*, and will be used to calculate the gradients as we go further up the graph, and be multiplied by other matrices. Apart from that, if we had started x or y to be matrices, it would have resulted in the same difficulty. Due to this reasons, we utilize a gradient tensor at the beginning of the algorithm. It is nothing but a vector passed onwards from the starting point, following the same process as before.

Passing along this vector won’t change our answers at all, for example, our Jacobian was Jx (or Jy), and with passing along this vector, we simply end up with [1, 1, 1, 1, 1]T. Jx , which will give us the original vector (the gradient of x or y), as doing the above mentioned operations reduces the matrix to a vector, which is what we desired in the first place (the dimension are (*1 * 5*) x (*5 * 5*) = *1 * 5*), giving us a vector. The main reason for passing in a vector in the last node was to reduce our output from a matrix to a vector, or whatever the dimension was of our input. Note that the gradient tensor has to match the dimensions of the function value (z).
Another added advantage is that we get control over the sensitivity of the output with respect to the input. If instead we passed in a gradient tensor [1, 1, 2, 1, 1], we will get the same output, except the third element will be twice of the original answer, as was intended. Overall, passing in a gradient tensor proves quite useful when calculating gradients of vector-valued functions. With this, we are done with the theory for Automatic Differentiation !